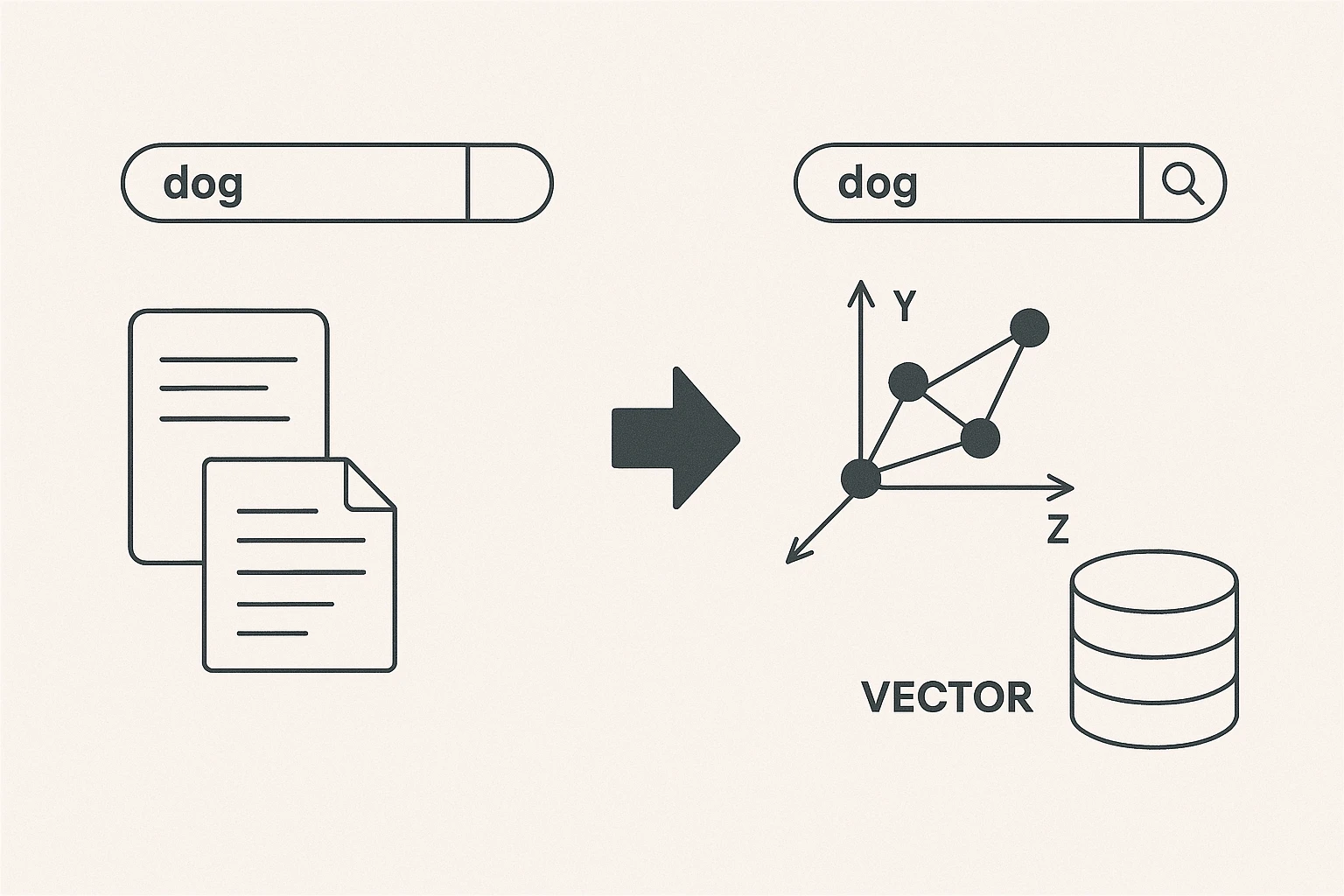
1. Lexical Search: The Starting Point
For many years, search engines and enterprise systems used what we call lexical search. In simple terms, this approach looks for exact keyword matches between a user’s query and the text documents in a database. While it’s straightforward and often fast, it can be misleading. For example, searching “last World Cup” using lexical methods might return results containing “I had my last cup of coffee,” simply because the words match, even though the meaning is off-topic.
2. The Shift to Semantic Search
Semantic search addresses those limitations by interpreting the meaning behind the user’s query rather than relying solely on word overlap. The core innovation here is the use of embeddings, which are numerical representations of words, phrases, or entire documents. These vectors capture semantic relationships: words or phrases with similar meanings end up closer together in a high-dimensional space. Consequently, a query like “last World Cup” will retrieve content specifically about the latest World Cup event—rather than coffee or unrelated “last cups”—because the system judges meaning instead of plain keyword overlap.
Why This Matters
- Contextual Relevance: You get answers that actually relate to your question.
- Greater Flexibility: Synonyms and related concepts are automatically recognized. A search for “manager” can also surface “team lead” or “boss.”
3. Enter Retrieval-Augmented Generation (RAG)
As powerful as semantic search is, modern Retrieval-Augmented Generation (RAG) goes a step further. RAG pairs large language models with real-time data retrieval:
- Retrieve: When a user poses a question—say about the resiliency of their Azure environment—the system queries relevant databases or documents using semantic search.
- Generate: The results are then fed into a large language model, which synthesizes a coherent, context-rich response.
By connecting an LLM to a knowledge source via semantic search, RAG solutions can provide up-to-date information, overcoming the static “cut-off” that many standalone language models have after training.
4. How Modern LLMs Benefit
Large Language Models—trained on vast amounts of text—excel at generating human-like responses. However, they don’t inherently update their knowledge once training finishes. Integrating semantic search allows them to:
- Stay Current: Pull relevant data from external sources.
- Enhance Accuracy: Filter out irrelevant details by focusing on the intent behind a user’s query.
- Use Hybrid Retrieval: Combine exact matches (like IDs, names, or specific technical terms) with semantic matches for broader context.
5. Putting It All Together
When orchestrated correctly—often via an orchestration engine—semantic search and LLMs deliver powerful, context-aware answers. From providing precise technical support to generating creative, yet factually grounded content, these technologies revolutionize how we interact with and leverage information.
In summary, the evolution from lexical to semantic search has dramatically improved the relevance and accuracy of information retrieval. Coupled with RAG and modern LLMs, we now have AI systems that not only understand your query’s intent but also retrieve the most fitting information on demand, giving you answers that are both meaningful and up-to-date.